How LLMs Actually Work: What Happens When You Talk to ChatGPT
You type something into ChatGPT. Maybe you ask it to explain quantum physics. Maybe you want it to debug your code. Two seconds later, a weirdly coherent answer starts streaming onto your screen, word by word.
What actually happened in those two seconds?
I've been obsessed with this question. Most explanations I found were either drowning in linear algebra or hand-waving with "it's trained on the internet." Both are useless if you actually want to understand the thing. So I spent weeks going deep, and this is my attempt at explaining it the way I wish someone had explained it to me.
The short version
Your text gets split into chunks (tokens). Those chunks become rich number sequences (embeddings). Those sequences get processed through dozens of transformer layers that figure out context and relationships between words. The output is a probability score for every possible next word. The model picks one. Repeats. Until the response is done.
That's the whole thing. Everything below is unpacking what each of those steps actually means.
Step 1: Tokenization — chopping text into digestible pieces
First thing to know: computers don't understand words. They understand numbers. So before anything interesting happens, your text gets chopped into small chunks called tokens, each mapped to a number.
But tokens aren't words. Think of it like a cookbook index. You don't list "Chicken Tikka Masala" as one entry. You list "Chicken" + "Tikka" + "Masala" separately so each piece is reusable across recipes.
Tokenizers do the same thing. Common words stay whole. Uncommon words get split:
| Text | Tokens |
|---|---|
| "the" | 1 token (super common) |
| "unhappiness" | "un" + "happiness" (2 tokens) |
| "cryptocurrency" | "crypt" + "ocur" + "rency" (3 tokens) |
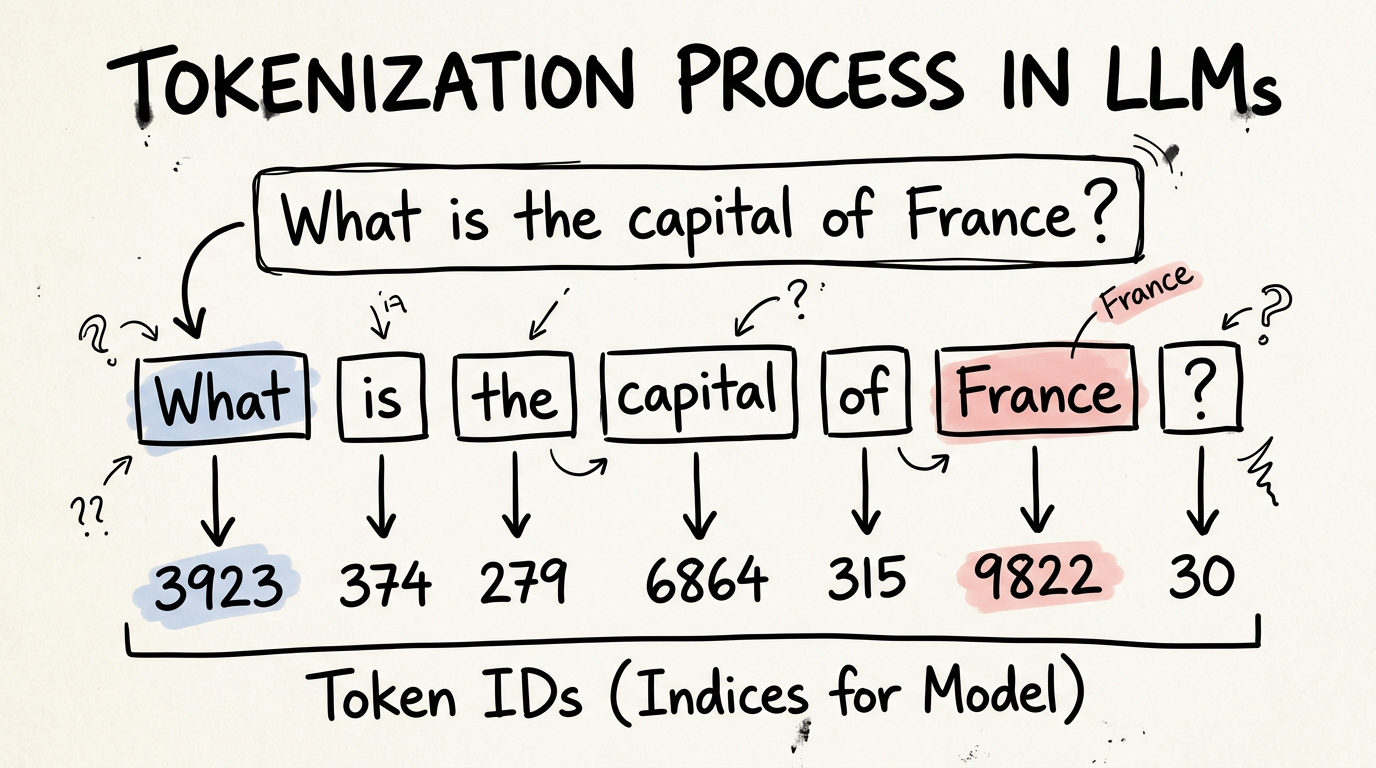
So when you type "What is the capital of France?" it becomes something like:
"What" → 3923
" is" → 374
" the" → 279
" capital" → 6864
" of" → 315
" France" → 9822
"?" → 30
Spaces are included in the tokens. That's how the model knows where words start.
The tokenizer itself is dumb. It's a lookup table and a splitting algorithm. No intelligence. It runs before the neural network even sees your input. About 100,000 entries can cover virtually any text — English, Hindi, code, emoji, whatever.
After this step, your message is just a list of numbers: [3923, 374, 279, 6864, 315, 9822, 30].
Step 2: Embeddings — making those numbers actually mean something
Here's the problem. Token 9822 is "France." Token 9823 might be "banana." The numbers are next to each other but the words have zero in common. It's like your phone contacts being alphabetical — "Adam" isn't more related to "Barbara" than to "Zara" just because they're adjacent in the list.
The network needs a representation where similar things have similar numbers. That's what embeddings do.
Each token gets converted into a vector — a long list of numbers. Not one number. Thousands. GPT-4 class models use 8,192 or more numbers per token.
Why so many? Think of it like describing countries:
| Country | Wealth | Temperature | Population | Region |
|---|---|---|---|---|
| France | 0.82 | 0.45 | 0.35 | 0.70 |
| Germany | 0.85 | 0.38 | 0.40 | 0.72 |
| India | 0.35 | 0.80 | 0.95 | 0.30 |
Four numbers and you can already see France and Germany are similar while India is different. Now imagine 8,192 dimensions instead of 4. You'd capture insanely subtle distinctions — cuisine, political system, historical alliances, everything.
That's an embedding. Each word lives in a high-dimensional space where words with similar meanings are physically close together. "France" is near "Germany" and "Italy." "France" is far from "banana."
The wild part: nobody hand-designed what those dimensions mean. The model figured out its own organization during training. Some dimensions roughly correspond to concepts like "is this a European country?" or "is this a verb?" But most encode abstract patterns that don't map to anything humans would name. The model found whatever representation works best for predicting the next word.
After this step, your message is a rich grid of meaningful numbers — 7 tokens, each with 8,192 values. Now the interesting part starts.

Step 3: The transformer — where context gets built
At this point, each word knows about itself but has zero idea about context. "Capital" doesn't know it's asking about France. "France" doesn't know someone wants its capital. They're isolated.
The transformer architecture fixes this. Its core innovation is called attention, and honestly, it's one of the most elegant ideas in computer science.
The cocktail party analogy
You're at a loud party. A hundred conversations happening at once. Then someone across the room says your name. Your brain instantly zeros in on that voice and filters out everything else.
Attention does the same thing for every word in a sentence. Each word asks: "which other words should I focus on right now?"
When the model processes "capital," the attention mechanism scores every other word for relevance. "France" gets a high score (capitals belong to countries). "What" gets a moderate score (signals this is a question). "Of" gets almost nothing (just a connector).
This happens through three things each word computes:
- Query: "What am I looking for?" ("capital" asks: which entity am I the capital of?)
- Key: "What do I have?" ("France" says: I'm a country name)
- Value: "Here's my actual information" ("France" provides its full meaning)
When a Query matches a Key, the model pays attention to that word's Value. Like a lock and key — "capital" is looking for a country, "France" is advertising it is one. They click.

Multiple attention heads
One attention head might focus on grammar. Another on meaning. Another on what kind of answer is expected. Transformers run many heads in parallel — like a panel of specialists examining the same sentence from different angles, then combining what they found.
Going deep
One attention + processing step is a transformer block. Modern LLMs stack 80 to 100+ of these blocks on top of each other. Each layer builds a more sophisticated understanding:
- Early layers: syntax, grammar, basic structure
- Middle layers: meaning, facts, reasoning patterns
- Late layers: nuance, context-specific behavior, complex logic
By the time your input passes through all of them, the model has built a deep understanding of your question. The vector for "France" now carries the information that someone is asking for its capital. The vector for "?" signals a concise answer is expected.
Step 4: Generating the response — one word at a time
This is the part that surprised me most when I first learned it.
The model takes the final processed vector and computes a probability for every single token in its vocabulary — all 100,000+ of them.
For "What is the capital of France?" the output looks roughly like:
| Token | Probability |
|---|---|
| "Paris" | 85% |
| "The" | 3% |
| "Lyon" | 2% |
| "It" | 1% |
| ... | (100,000+ others with tiny probabilities) |
It picks "Paris."
Then — and this is key — it takes the entire input (your question + "Paris") and runs the whole network again to predict the next token. Then again. And again. Every single token you see streaming across your screen required a complete pass through the entire neural network.
A 500-word response means hundreds of full passes through billions of calculations. That's why these things need serious hardware.

Why responses feel "creative"
The model doesn't always pick the highest-probability word. It samples — sometimes picking the second or third most likely option. This is controlled by temperature:
- Low temperature: almost always picks the top choice. Safe, predictable, boring.
- High temperature: more willing to take risks. Creative, surprising, occasionally unhinged.
This is why you get different answers to the same question. The model isn't pulling from a database. It's generating fresh output each time with randomness baked in.
How it learned all this
Everything above — the embeddings, the attention weights, the feed-forward networks — is billions of numbers. GPT-4 class models have hundreds of billions of them. They're called weights or parameters, and they are the model's knowledge.
How did those numbers get their values?
Imagine an empty library
You open a brand new library with 100,000 books and no organizational system. Day one, books are placed randomly. Cookbooks sit next to physics textbooks.
Someone asks for "something like this Indian cookbook." You check what's nearby — it's a quantum mechanics textbook. Useless. But you learn. You nudge the Indian cookbook closer to where the Italian cookbook is.
Hundreds of thousands of interactions later, every book has been nudged into a meaningful position. Cookbooks cluster together. Within that cluster, Indian cookbooks are near Thai cookbooks. You never created a "cookbooks" category. The organization emerged from repeated corrections.
Training works exactly like this
Before training, every weight is random. The entire model is gibberish.
Then it sees a sentence: "The capital of France is ___." It guesses "banana" with 0.2% confidence. The right answer, "Paris," got 0.001%.
The loss function measures how wrong this was. Backpropagation traces through the network and figures out which weights caused the error. Each weight gets nudged slightly toward a better answer.
Then the next example. And the next. Billions of times, across trillions of words of text — books, Wikipedia, code, conversations, forums.
After months on thousands of GPUs, those random numbers have been nudged into values that encode grammar, facts, reasoning, coding ability, and the ability to hold a conversation. Nobody programmed these capabilities. They emerged from the process of predicting the next word, repeated at insane scale.
Why scale matters
Quick comparison to ground this:
| Small Model | Frontier Model (GPT-4 / Claude class) | |
|---|---|---|
| Parameters | ~100K | 100-300+ billion |
| Layers | 2-3 | 80-100+ |
| Embedding dimensions | 64 | 8,192-16,384 |
| Training data | A few MB | Trillions of tokens |
| Training time | Minutes on a laptop | Months on thousands of GPUs |
| Weight file size | ~400 KB | 200-600 GB |
That weight file — the massive blob of learned numbers — is the model. When a company ships an LLM, they're shipping this file plus inference code. The intelligence is entirely in those numbers.
Something genuinely strange happens at scale: capabilities emerge that nobody trained for. A model trained only to predict the next word somehow learns to write code, do math, translate languages, and reason about abstract problems. Nobody programmed these abilities. They fell out of next-word prediction at sufficient scale.
I don't think we fully understand why this happens yet. That's both exciting and a little terrifying.
So what's actually happening when you talk to an AI?
Your words get shredded into tokens. Those tokens become rich numerical representations. Dozens of transformer layers let every word examine every other word, building a layered understanding of your question. The network produces a probability distribution over its entire vocabulary, picks a word, repeats hundreds of times, and you get your answer.
No database lookup. No keyword matching. No pre-written responses. Just matrix multiplication — billions of numbers multiplied in patterns shaped by trillions of words of human text.
The fact that this works at all is, honestly, kind of insane. And we're still very early.
If this helped something click, I write more about AI, products, and distribution at nakulmk.com. More posts coming soon.